Architettura di riferimento per la previsione delle perdite di credito
Unifica portafogli di prestiti, scenari economici e modelli di rischio sulla piattaforma di intelligenza dei dati Databricks per alimentare test di stress e CECL scalabili, trasparenti, verificabili e a costi efficienti.
Che cosa imparerai
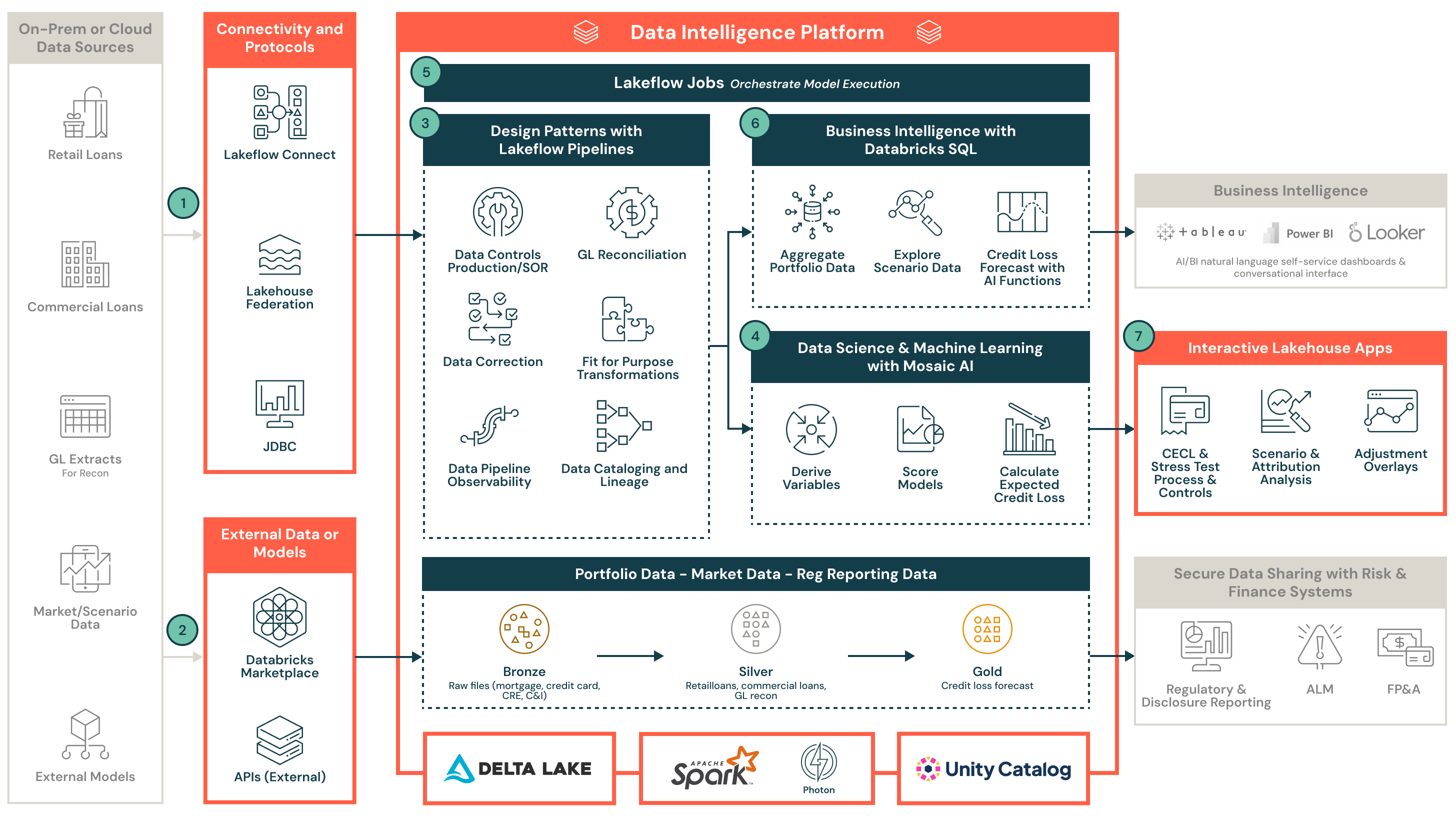
- Un'architettura lakehouse end-to-end per l'ingestione e l'unificazione di prestiti al dettaglio, prestiti commerciali, dati del libro mastro generale (GL) e scenari macroeconomici
- Come la Federazione Lakehouse e Lakeflow Connect supportano l'integrazione sicura, scalabile e dei dati tra sistemi cloud e on-premise
- L'uso di lakehouse per standardizzare, conciliare e controllare la qualità dei dati per l'esecuzione del modello a valle
- Come operazionalizzare i modelli costruiti in Python, R o SAS utilizzando Mosaic AI e orchestrare i flussi di lavoro con Databricks Workflows
- Uno strato di calcolo scalabile utilizzando i cluster Databricks per supportare il CECL su larga scala e i test di stress
- Un catalogo centralizzato di dati e modelli, modello di sicurezza e controlli con Unity Catalog per far rispettare la genealogia dei dati, l'auditabilità e la conformità normativa
- Come Lakehouse Apps consente una collaborazione sicura, aggiustamenti e approvazione delle previsioni tra i team di rischio di credito e finanza
Modernizza le tue previsioni di perdita di credito per CECL e Stress Test
- Fonti di dati del portafoglio e ingestione
- Accedi e ingesta prestiti al dettaglio, prestiti commerciali e dati di esposizione correlati
- Ingestisci i dati GL, inclusi conteggi degli account e saldi in sospeso, per la riconciliazione e l'integrità dei dati
- Usa Lakeflow Connect per l'ingestione nativa basata su CDC da sistemi di dati on-premise o cloud, o sfrutta Lakehouse Federation per un accesso ai dati sicuro, scalabile e senza duplicazioni
- Dati di scenario macroeconomico
- Collega e acquisisci dati di scenario macroeconomico, come gli scenari di Moody, tramite API
- Incorpora una logica di espansione dello scenario personalizzata o ingesta direttamente nel piattaforma i set di dati dello scenario interno
- Governance e gestione dei dati
- Utilizza Unity Catalog per centralizzare la governance dei metadati su dati del portafoglio, dati dello scenario, output del modello, sovrapposizioni e report di divulgazione. Il tracciamento della discendenza garantisce l'affidabilità dei dati e la prontezza per l'audit.
- Abilita l'integrazione multi-classe di attività, standardizzando i dati dei prestiti al dettaglio e commerciali con controlli di accesso a livello di riga
- Esegui controlli sulla qualità dei dati e riconciliazione GL nelle tabelle Silver curate e approva i controlli sui dati
- Sfrutta le tabelle di sistema e le tracce di audit integrate per una piena auditabilità e conformità con gli standard normativi
- Implementa l'esecuzione del modello
- Implementa o importa modelli sviluppati in Python, R o SAS. Registra i modelli in MLflow.
- Definisci la logica per la derivazione delle variabili, il punteggio del modello e i calcoli delle perdite di credito attese (ECL) per scenario e orizzonte temporale
- Flussi di lavoro CECL e test di stress
- Crea flussi di lavoro per l'analisi degli scenari, l'analisi della sensibilità e l'analisi dell'attribuzione
- Esegui workflow su larga scala utilizzando Databricks Workflows, fornendo automazione, monitoraggio e programmazione per pipeline di modelli complessi
- Business Intelligence
- Usa Databricks SQL per rivedere e analizzare i dati del portafoglio e i dati dello scenario
- Conduci un'analisi delle perdite di credito a livello di prestito per ogni scenario e orizzonte
- Esplora i risultati in modo interattivo e valida le ipotesi con piena trasparenza e tracciabilità
- Collaborazione tra rischio di credito e finanza
- Abilita la collaborazione in tempo reale tra i team di rischio di credito e finanza tramite Lakehouse Apps (applicazioni web)
- Carica fogli di calcolo per l'elaborazione finale dell'utente per supportare le valutazioni individuali
- Applica sovrapposizioni di gestione e controlli di approvazione, e integra con i sistemi di rischio e finanza a valle per la registrazione GL, la segnalazione di divulgazione e altro
Vantaggi
- Conformità normativa e auditabilità
Garantisci la conformità con CECL, CCAR, IFRS 9 e altri quadri normativi attraverso la genealogia dei dati automatizzata, i controlli incorporati e i flussi di lavoro pronti per l'audit - Prestazioni scalabili per calcoli complessi
Esegui modelli e scenari di perdita di credito con facilità utilizzando l'autoscaling dei cluster Databricks progettati per carichi di lavoro finanziari ad alta intensità di calcolo - Architettura a basso costo
Sfrutta un modello di prezzo basato sul consumo senza ulteriori costi di licenza software - risultando in un TCO inferiore e un utilizzo flessibile delle risorse allineato alla tua domanda - Piattaforma pronta per l'impresa e sicura
Incorporata sicurezza, gestione dell'identità e governance le capacità assicurano che i dati di rischio sensibili siano protetti e gestiti in conformità con gli standard aziendali e normativi - Autoservizio con personalizzazione completa
Abilita i team interni a gestire e adattare il loro ambiente di modellazione attraverso una piattaforma di autoservizio, pur supportando la personalizzazione completa, l'automazione e l'integrazione con i sistemi aziendali
Consigli

Architettura dei settori industriali
Architettura di riferimento per la gestione degli investimenti nei servizi finanziari

Architettura di riferimento
Intelligent Data Warehousing su Databricks

Architettura di riferimento
Architettura di riferimento per l'ingestione dei dati

Architettura di riferimento
Architettura end-to-end di Data Intelligence con Azure Databricks

Architettura dei settori industriali
Architettura di riferimento per le analitiche della sottoscrizione assicurativa
Architettura dei settori industriali
Architettura di riferimento per l'ottimizzazione della distribuzione nel settore assicurativo