Databricks上のインテリジェントデータウェアハウジング
このリファレンスアーキテクチャは、ストリーミングとバッチの取り込み、管理されたストレージ、スケーラブルなSQL分析、統合されたAIを組み合わせることで、DatabricksデータインテリジェンスプラットフォームがモダンなデータウェアハウジングとBIをどのように可能にするかを示しています。これは、統一されたレイクハウス上で行われます。
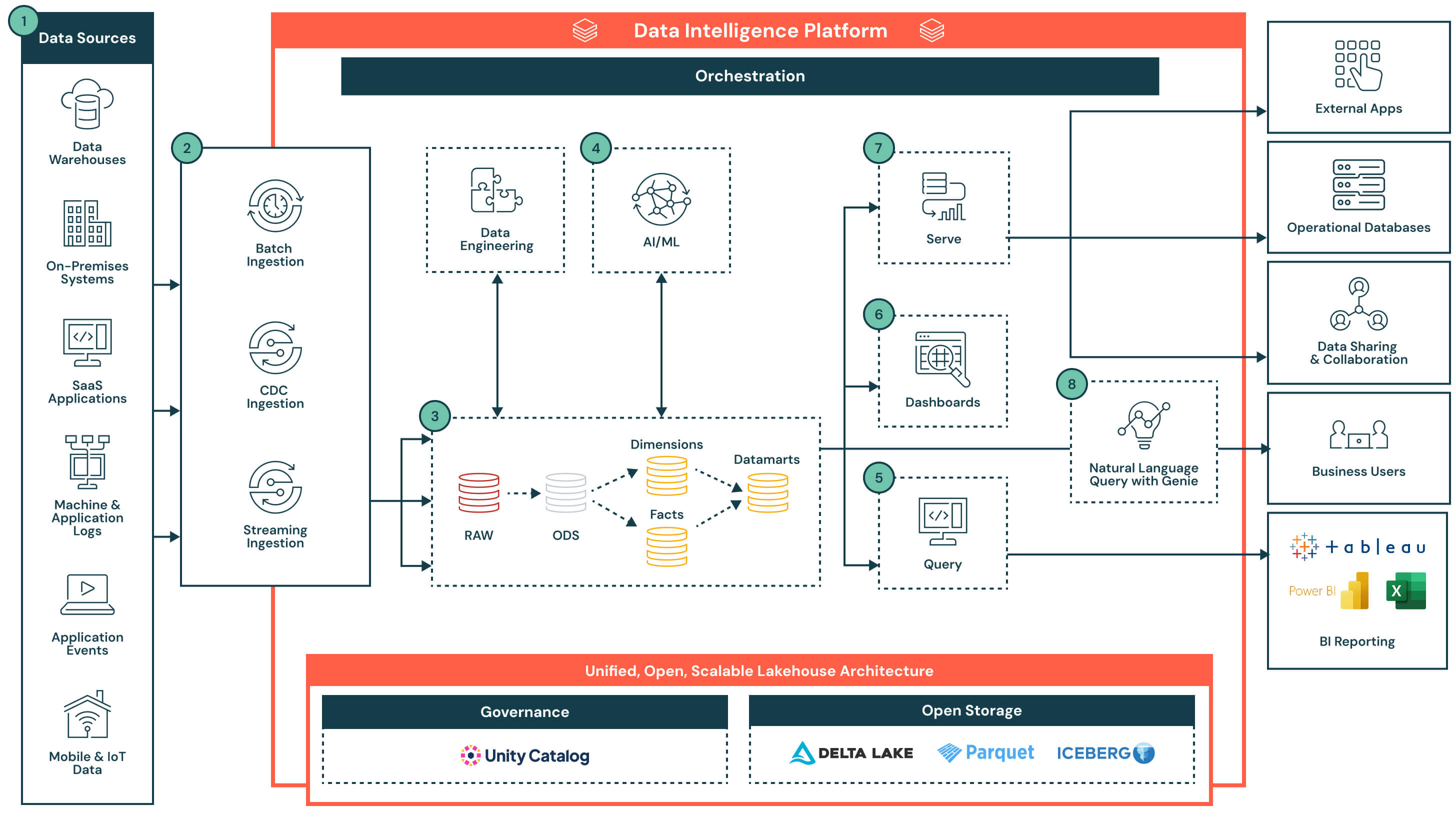
アーキテクチャの概要
このアーキテクチャは、伝統的なレポーティング、リアルタイムダッシュボード、予測モデリング、セルフサービス分析をサポートし、セキュリティ、ガバナンス、パフォーマンスのエンタープライズスタンダードを満たしています。
このソリューションは、Databricks SQLによって駆動されるDatabricksデータインテリジェンスプラットフォームが、データチームとビジネスステークホルダーの両方のニーズを満たしながら、組織がデータウェアハウジング戦略を近代化する方法を示しています。
アーキテクチャは、Unity Catalogによって管理されるオープンで統制されたレイクハウスから始まります。データは、運用データベース、SaaSアプリ、イベントストリーム、ファイルシステムを含むさまざまなシステムから取り込まれ、中央のストレージ層に格納されます。プラットフォームのデータインテリジェンスは、ETLやSQL分析からダッシュボードやAIのユースケースまで、すべてを支えます。SQL、BIツール、自然言語クエリを通じて柔軟なアクセスをサポートすることで、プラットフォームはデータ製品の提供を加速し、組織全体で洞察を利用可能にします。
ユースケース
技術ユースケース
- 多様なソースからの構造化、非構造化、バッチ、ストリーミングデータの取り込み
- 堅牢な宣言型ETLパイプラインの構築
- メダリオンアーキテクチャを使用して事実、次元、データマートをモデリング
- レポートやダッシュボードのための高並行SQLクエリの実行
- MLの出力を直接ウェアハウスに統合し、下流での使用を可能にします
ビジネスユースケース
- 売上、運用、顧客指標に関するリアルタイムのダッシュボードの提供
- Genieのような自然言語インターフェースを通じてアドホックな探索を可能にする
- 需要予測やチャーンモデリングのような予測ユースケースをサポートします
- 部門間やパートナーとの間で管理されたデータ製品の共有
- 財務、マーケティング、製品チームに対して迅速で信頼性の高い洞察を提供します
データインテリジェンスによる主要な機能
このアーキテクチャのデータインテリジェンスコンポーネントは、プラットフォームをよりスマートで適応性があり、さまざまなユーザーやワークロードで使いやすくします。システム全体でAIとメタデータの認識を適用し、体験を簡素化し、意思決定を自動化します:
- 自然言語インターフェース(ジニー): ビジネスの文脈を理解し、ユーザーがデータに関する質問を平易な言葉で尋ねることを可能にします
- セマンティック認識: テーブル、列、使用パターンの関係を認識し、結合、フィルタ、計算を提案します
- 予測最適化: 過去のワークロードに基づいてクエリのパフォーマンスと計算の割り当てを継続的に調整します
- 統一されたガバナンス: データ資産のタグ付け、分類、使用状況の追跡を行い、発見をより直感的で安全にします
- 主要な機能: あなたのデータとユーザーに適応する自己最適化プラットフォーム
- 差別化要素: データインテリジェンスは、取り込み、クエリ、ガバナンス、可視化全体に組み込まれています - 後付けではありません
キーケイパビリティとディフェレンシエーターによるデータフロー
- データソース: データは、エンタープライズアプリ(例:SAP、Salesforce)、データベース、IoTデバイス、アプリケーションログ、外部APIなど、さまざまなシステムに保存されます。これらのソースは、構造化、半構造化、非構造化のデータを生成することができます。
- データ取り込み: バッチジョブ、変更データキャプチャ(CDC)、ストリーミングを通じてデータを取り込みます。これらのパイプラインは、ソースシステムとユースケースに応じて、ほぼリアルタイムまたはスケジュールされた間隔でレイクハウスアーキテクチャにフィードします。
- 主な差別化要素: すべてのモダリティ - バッチ、ストリーミング、CDC - の統一された取り込みを提供し、別々のインフラストラクチャやパイプラインを必要としません
- データ変換、ETL、宣言的パイプライン: 取り込まれたデータは、メダリオンアーキテクチャ を通じて変換され、生のデータから精製されたデータへと段階的に洗練されます。
- Raw zoneからBronze zoneへ: 外部ソースシステムから取り込まれたデータは、このレイヤーの構造がソースシステムのテーブル構造に「そのまま」対応し、データに変換や更新が行われません
- Bronze zoneからSilver zoneへ: 受信データを標準化し、クリーニングします
- シルバーゾーンからゴールドゾーンへ: ビジネスロジックを適用して再利用可能なモデルを作成します
- 事実と次元 → データマート: 下流の分析のためにデータを集約し、キュレーションします
- 主要な差別化要素: 組み込みの系統、観察可能性、スキーマ進化を持つ宣言型、本番環境向けパイプライン
- AIユースケースのための精製データ: データマートからの精製データは、機械学習モデルの訓練や適用に使用できます。これらのモデルは、需要予測、異常検出、顧客スコアリングなどのユースケースをサポートします。
- モデルの出力は、SQLやダッシュボードを介して簡単にアクセスできるように、伝統的なウェアハウスデータと一緒に保存されます
- 結果は、要件に応じてスケジュールで更新されるか、リアルタイムでスコアリングされます
- 主な差別化要素: 同じプラットフォーム上での分析とAIワークロードの共存 — データ移動は不要。モデルの出力はネイティブで、クエリ可能な管理資産として扱われます。
- クエリ供給BIレポーティングツール: Databricks SQLは、サーバーレスコンピューティングを通じて高並行性、低レイテンシのクエリをサポートし、人気のあるBIツールに簡単に接続します。
- 組み込みのクエリエディターとクエリ履歴
- クエリは、データマートからの管理された最新の結果や、豊かなモデルの出力を返します
- 主な差別化要素: Databricks SQLは、BIツールがデータを直接クエリすることを可能にします - 複製なしで - 複雑さを減らし、追加のライセンス費用を避け、全体的なTCOを低減します。サーバーレスコンピューティングとインテリジェントな最適化と組み合わせることで、最小限のチューニングでウェアハウス級のパフォーマンスを提供します。
- ダッシュボード: Databricks内で直接作成することも、Power BIやTableauのような外部のBIツールで作成することもできます。ユーザーは視覚化を自然言語で説明し、Databricks Assistantが対応するチャートを生成します。これらは、ポイントアンドクリックのインターフェースを使用して洗練することができます。
- 自然言語入力を使用して視覚化を作成します
- フィルターやドリルダウンを使用してダッシュボードを対話的に変更し、探索します
- ダッシュボードを組織全体で公開し、安全に共有します。これには、Databricksワークスペースの外部のユーザーも含まれます
- 主な差別化要素: 管理されたリアルタイムデータ上でダッシュボードを構築し、探索するためのローコードとAI支援の体験を提供します
- 精製データの提供: 精製されたデータは、ダッシュボードを超えて提供することができます:
- トランザクションの意思決定のための下流のアプリケーションや運用データベースと共有します
- 分析のための共同ノートブックで使用します
- 統一されたガバナンスでパートナー、チーム、または外部の消費者にデルタ共有を介して配布
- 自然言語クエリ(NLQ): ビジネスユーザーは自然言語を使用して統制されたデータにアクセスできます。この会話型の体験は、生成型AIによって強化され、チームが静的なダッシュボードを超えてリアルタイムの自己サービスの洞察を得ることを可能にします。NLQは、Unity Catalogからの組織のセマンティクスとメタデータを活用して、ユーザーの意図をSQLに変換します。
- ダッシュボードに事前に組み込まれていないアドホック、インタラクティブ、リアルタイムの質問をサポートします
- 時間とともに進化するビジネス用語と文脈に知的に適応します
- Unity Catalogを通じて既存のデータガバナンスとアクセス制御を活用します
- コンプライアンスと透明性のための自然言語クエリの監査可能性と追跡可能性を提供します
- 主要な差別化要素: 進化するビジネス概念に継続的に適応し、SQLの専門知識を必要とせずに正確で、コンテキストに応じたレスポンスを提供します
- プラットフォームの機能:ガバナンス、パフォーマンス、オーケストレーション、オープンストレージ: このアーキテクチャは、セキュリティ、最適化、自動化、データライフサイクル全体での相互運用性をサポートするプラットフォームネイティブの機能セットによって支えられています。主な機能:
- ガバナンス: Unity Catalogは、すべてのワークロードに対して一元化されたアクセス制御、系統、監査、データ分類を提供します
- パフォーマンス: Photonエンジン、インテリジェントキャッシング、ワークロード認識の最適化が、手動のチューニングなしで高速なクエリを提供します
- オーケストレーション: 組み込みのオーケストレーションは、データパイプライン、AIワークフロー、バッチとストリーミングのワークロードを跨いでスケジュールされたジョブを管理し、依存関係管理とエラーハンドリングのネイティブサポートを提供します
- オープンストレージ: データはオープンフォーマット(Delta Lake、Parquet、Iceberg)で保存され、ツール間の相互運用性、プラットフォーム間の移植性、ベンダーロックインなしの長期的な耐久性を可能にします
- 監視と監査可能性: クエリパフォーマンス、パイプライン実行、ユーザーアクセスのエンドツーエンドの可視性を提供し、より良い制御とコスト管理を実現します
- 主な差別化要素: プラットフォームレベルのサービスは統合されており、レイヤー化されていません。これにより、ガバナンス、自動化、パフォーマンスがすべてのデータワークフロー、クラウド、チーム間で一貫しています


